
For most people who watched the Disney animated movie Big Hero 6, having a kind and empathetic robot companion like the character Baymax to protect, teach, and support you seems like straight-up science fiction. But for NYU Shanghai Professor of Practice in Computer Science Wilson Tam Yik-Cheung (and now many of his undergraduate students), creating a Baymax to help you and me and everyone we know is well within the realm of possibility. The key is getting AI to communicate with us by understanding, responding to, and producing real human language (aka “natural language”), a feat that Tam and his students are working toward in his class, CSCI-SHU 376 Natural Language Processing.
Natural language processing (NLP) is making tech more accessible and useful in our everyday lives, driving applications like voice activated personal assistants, customer service help bots, machine translation, automatic transcription, machine reading, and even music generation. In Tam’s course, NYU Shanghai students build on foundational skills from prior coursework in machine learning, probability, and statistics to refine and apply the state-of-the-art artificial intelligence (AI) algorithms that power language-based services like Google Translate, Amazon Echo and Apple’s Siri.
Tam first began working with language technologies, especially voice recognition, as a master’s degree student at Hong Kong University of Science and Technology. He then specialized in computer language generation during his PhD studies at Carnegie Mellon University’s School of Computer Science. “I was fascinated to see so many applications developed using language technologies and applied to our daily life,” Tam says. “Creating a conversational interface for computers to communicate with humans seemed like such a cool thing to have in the future, just like a scene from a sci-fi movie.”
Tam worked for Microsoft to help develop their personal assistant Cortana before joining Tencent , where he helped develop several AI dialogue systems, including their WeChat-based personal assistant program Xiaowei and chatbot Xianer, which aims to help users resolve personal anxiety issues with responses modeled on advice from Buddhist monks at Zhejiang Province’s famous Longquan Temple. When he’s not teaching or advising students on NLP-based research projects, Tam is working on a mental health support AI that can help people navigate past moments of psychological crisis and connect users with serious mental health emergencies to human professionals.

Tam introduces Tencent’s voice-enabled personal assistant Xiaowei at the Tencent Global Digital Ecosystem Summit in 2019.
“The data from Xianer and many similar projects shows that most people ask questions about topics like marriage, study, money, how to raise their kids -- topics that they have no idea how to find some help about,” says Tam. “Often people who need help are isolated, and they don’t have many friends, so this robot can listen to them, keep track of their problems, and try to find an answer that can help them and comfort them.”
As a Hong Kong native, Tam is fluent in English, Cantonese, and Mandarin Chinese, and in the course of his academic research and professional experience he has learned about the linguistic structures of other languages, including Arabic and French. But surprisingly, Tam says that cutting-edge NLP research doesn’t require programmers to have extensive knowledge of each language their AI is working with.
“The languages of Chinese and English have important differences in terms of syntactical behavior. However, in terms of machine learning, actually we apply similar techniques to both languages, so the techniques are universal,” Tam says. That’s because contemporary NLP uses what’s known as a data-driven approach, which trains AI to understand and use language in much the same way that human babies learn to talk. Instead of starting out by teaching AI a set of grammar rules and only later giving the AI real examples labeled with grammatical markers, programmers now begin pre-training NLP AI by inputting billions of unlabeled natural language data points (such as Wikipedia articles and even whole books), allowing the AI to learn through a series of massive fill-in-the-blank exercises.
Using free processing units provided by Google, Tam’s students can feed tens and even hundreds of thousands of data points – phrases, sentences, and dialogues created and used by real people in texts, online, in social media, and in linguistics research datasets – into “neural networks.” Neural networks are multi-layered webs of small computing units, modeled after the structure of human neurons. Not only can these networks process massive amounts of data in a relatively short time, they can also sift out more insightful answers to complex questions by developing massive computational trees relating single data points to thousands of others in milliseconds. That’s a huge advantage when just a single word, or “token,” in a dataset can be linked to an average of 768 “features” – linguistic elements ranging from synonyms, to suffixes, to words and phrases that are often used together with the token.
“Learning how to work with neural networks is one of the biggest challenges for students in this course,” Tam says. “It requires a strong foundation in probability theory, and the many layers of a neural network require students to do a lot of parallel processing – formulating data in multiple dimensions.”
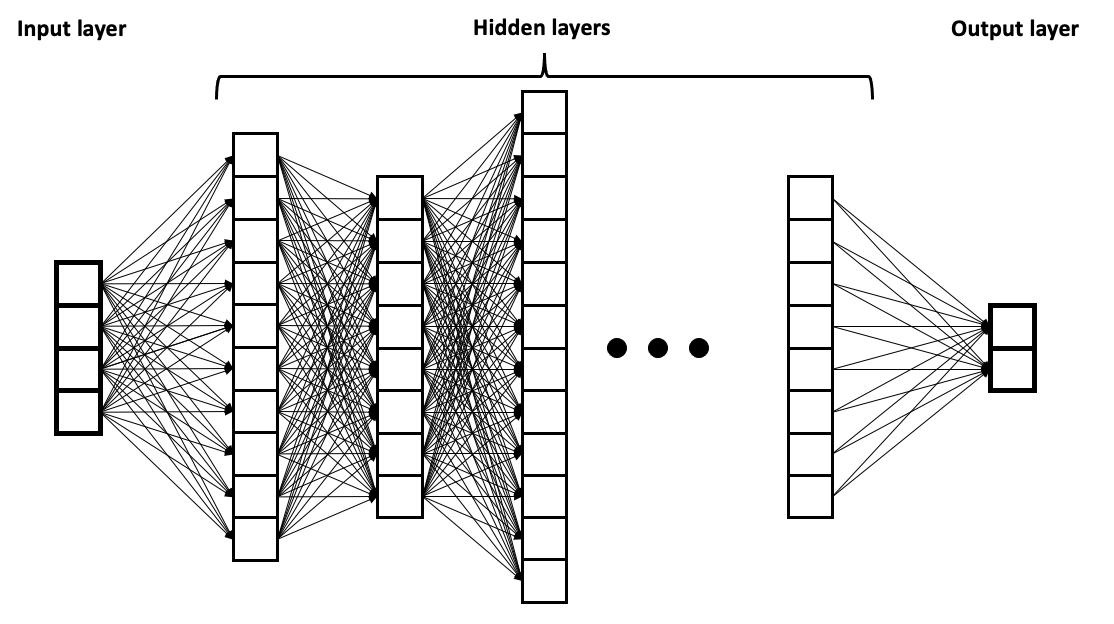
A visual representation of how the computing units in a neural network interact with each other. Image by BrunelloN via Wikimedia Commons.
{kind=link}
In homework assignments and final projects, students re-craft the cutting-edge NLP algorithms that govern their neural networks, directing the networks to rebalance the weight of particular token-associated features to make predictions and outputs that fit the task at hand. Their final projects have ranged from turning computers into Classical Chinese poets to teaching them the basics of humor through automated meme generation. Some students were even able to go beyond the confines of Chinese and English in machine translation applications, in one project harnessing French to English translation to improve the accuracy of French to Norwegian translation.
Wang Yuchen ’22, a double major in data science and computer science, says he was really excited to put his programming skills to the test in this rapidly emerging field. “Before taking this course, I knew some applications of NLP technology, such as machine translation and dialogue systems, but I knew little about its theory. I loved how the course projects let us apply what we learned and get our hands dirty through practice.”
For their open-ended final course project, Wang and his partner William Huang ’22 built their own meme caption generating program with some help from the OpenAI’s neural network CLIP, which is trained to extract meaningful responses that include images and text. Wang and Huang tried out several different caption generation processes, introducing tests of a caption’s suitability at various points in the generation process and matching them to different sets of real-world examples to carefully hone the AI’s abilities.

Two meme captions that Wang and Huang’s AI successfully generated, in part based on the captions listed as “Reference.”
“In conventional image captioning, the desired captions mostly identify the most salient objects in the images and describe their relationships. By contrast, meme captions are often based on more subtle features, like facial expressions and body languages, that inspire a sense of humor,” Wang said. “There were a few unexpected things we encountered, but Professor Tam was so helpful that everything went smoothly.”
Now Wang is using his NLP skills for good in his spare time, most recently trying to improve question and answer systems for Indian languages in a competition hosted by Google-backed data science community Kaggle. “I wanted to learn more about how to improve NLP models on underrepresented languages and practice what I learned from the NLP class,” he said.
Tam says he is excited to see students taking a passion for NLP work into new domains and new paths. “Once students have got their hands dirty and started building their own computer programs in this class, they will be ready to go into industry or graduate study, where there are a lot of opportunities to develop NLP technologies and related applications like computer vision,” Tam says.